liste sıralı değer kümesidir, her bir değer bir indis ile erişilmektedir. Listeyi oluşturan değerlere öğeler denilmektedir. Listeler karakter dizilerine, karakterlerden oluşan sıralı kümeler, benzer, tek farkı listelerin öğeleri herhangi bir tipte olabilir. Listeler ve karakter dizileri – ve sıralı küme şeklinde davranan diğer şeyler – diziler (sequences) adını almaktadır.
9.1 Liste değerleri
Liste yaratmanın bir çok yolu vardır; en kolayı öğeleri köşeli parantezlerle ([ ve ]) kapsamaktır:
[10, 20, 30, 40]
["spam", "bungee", "swallow"]
İlk örnek dört tamsayıdan oluşan bir listedir. İkincisi ise üç karakter dizisinin bir listesidir. Listenin öğeleri aynı tipten olmak zorunda değildir. Aşağıdaki liste bir karakter dizisi, bir kayan noktalı sayı, bir tamsayı ve bir başka liste (mirabile dictu) içermektedir:
["hello", 2.0, 5, [10, 20]]
Liste içerisindeki listeye içiçe liste adı verilir.
Son olarak, öğe içermeyen özel bir liste vardır. Boş liste adını alır ve [] ile temsil edilir.
Nümerik 0 değeri ve boş karakter dizisi gibi boş liste de boolean değer olarak yanlıştır (“false”):
>>> if []:
... print 'This is true."
... else:
... print 'This is false."
...
This is false.
>>>
Liste yaratmanın bütün bu yöntemleri yanında, liste değerlerini başka değişkenlere atayamasak veya listeleri fonksiyonlara parametre olarak geçiremezsek bu bir hayal kırıklığı yaratır. Ancak bunları yapabiliyoruz:
>>> vocabulary = ["ameliorate", "castigate", "defenestrate"]
>>> numbers = [17, 123]
>>> empty = []
>>> print(vocabulary, numbers, empty)
['ameliorate', 'castigate', 'defenestrate'] [17, 123] []
9.2 Öğelere erişme
Listenin öğelerine erişme sözdizimi, karakter dizisindeki karakterlere erişimin sözdizimiyle aynıdır. Köşeli parantez ([], boş liste ile karıştırılmamalıdır) işleci kullanılmaktadır. Köşeli parantezlerin içerisindeki ifade indisi belirtmektedir. İndislerin 0’la başladığını hatırlayın:
>>> print(numbers[0])
17
Her hangi bir tamsayı ifade indis olarak kullanılabilir:
>>> numbers[9-8]
5
>>> numbers[1.0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: list indices must be integers
Olmayan bir öğeyi okumak ve yazmak isterseniz, bir çalışma zamanı hatasıyla karşılaşırsınız:
>>> numbers[2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
Eğer indis negatif bir sayı ise, listenin sonundan geriye doğru sayacaktır:
>>> numbers[-1]
5
>>> numbers[-2]
17
>>> numbers[-3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
numbers[-1] listenin son öğesi, numbers[-2] sondan önceki öğe, ve numbers[-3] yok.
Döngü değişkenini liste indisi olarak kullanmak sık yapılan bir şeydir.
horsemen = ["war", "famine", "pestilence", "death"]
i = 0
while i < 4:
print(horsemen[i])
i += 1
Bu while döngüsü 0’dan 4’e kadar saymaktadır. Döngü değişkeni i 4 olduğunda, koşul sağlanmayacak ve döngü bitecektir. Döngünün gövdesi i değişkeni 0,1,2, ve 3 iken işletilecektir.
Döngüdeki her bir turda, i değişkeni listede indis olarak kullanılmakta, ve listenin i. öğesi ekranda görüntülenmektedir. Bu şekildeki kullanıma liste dolaşımı adı verilmektedir.
9.3 Liste boyutu
len fonksiyonu listenin boyutunu döndürür, boyut öğelerin sayısına eşittir. Bu değeri bir döngünün üst değeri olarak kullanmak, sabit bir sayı kullanmaktan daha mantıklıdır. Bu şekilde listenin boyutu değiştiğinde, programdaki tüm döngüleri değiştirmeniz gerekmez. Hepsi doğru bir şekilde her türlü boyutta liste için çalışır:
horsemen = ["war", "famine", "pestilence", "death"]
i = 0
num = len(horsemen)
while i < num:
print(horsemen[i])
i += 1
Döngü gövdesinin son çalışmasına, i len(horsemen) - 1 eşittir, bu da son öğenin indisidir. i‘nin değeri len(horsemen)‘e eşit olduğunda, koşul sağlanmayacak ve döngü gövdesi işletilmeyecektir, bu iyi bir şeydir çünkü len(horsemen) geçerli bir indis değildir.
Her ne kadar liste başka bir liste içerse de, içteki liste tek bir öğe olarak sayılacaktır. Aşağıdaki listenin boyutu 4’tür:
['spam!', 1, ['Brie', 'Roquefort', 'Pol le Veq'], [1, 2, 3]]
9.4 Liste üyeliği
in işleci bir dizi içerisindeki üyeliği sınayan bir boolean işleçtir. Daha önce karakter dizileriyle kullanmıştır, bu işleç liste ve diğer dizilerde de işe yarar:
>>> horsemen = ['war', 'famine', 'pestilence', 'death']
>>> 'pestilence' in horsemen
True
>>> 'debauchery' in horsemen
False
pestilence öğesi horsemen listesinin bir üyesi olduğundan, in işleci True sonucunu döndürmektedir. Ancak debauchery listede olmadığı için, in işleci False döndürmektedir.
not işlecini in işleciyle birlikte bir öğe listenin üyesi mi değil mi sınaması için kullanabiliriz:
>>> 'debauchery' not in horsemen
True
9.5 Liste işlemleri
The + işleci listeleri birleştirir:
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = a + b
>>> print(c)
[1, 2, 3, 4, 5, 6]
Benzer şekilde, * işleci verilen sayıda tekrarlar:
>>> [0] * 4
[0, 0, 0, 0]
>>> [1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
İlk örnek [0] listesini dört kere tekrarlamıştır. İkinci örnek ise [1, 2, 3] listesini üç kere tekrarlamaktadır.
9.6 Liste dilimleri
Karakter dizilerinde gördüğümüz dilim işlemleri listelerde de işe yaramaktadır:
>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> a_list[1:3]
['b', 'c']
>>> a_list[:4]
['a', 'b', 'c', 'd']
>>> a_list[3:]
['d', 'e', 'f']
>>> a_list[:]
['a', 'b', 'c', 'd', 'e', 'f']
9.7 The range fonksiyonu
Sıralı tamsayı içeren listeler sıklıkla karşılaştığımız bir durumdur, bu yüzden Python bunları yaratmak için kolay bir yol sunmaktadır:
>>> list(range(1, 5))
[1, 2, 3, 4]
range fonksiyonu iki argüman alır ve ilk argümandan ikinci argümana kadar ilk argümanı içeren, ancak ikinci argümanı içermeyen tüm tamsayıları içeren bir liste döndürür..
range fonksiyonunun iki biçimi daha vardır. Tek parametre alan biçimi 0 ile başlayan bir liste döndürür:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Eğer üçüncü bir parametre alıyorsa, bu parametre peşpeşe değerler arasındaki artış miktarını, adım sayısını belirler. Aşağıdaki örnek 1’den 10’a kadar 2’şerli artan bir listeyi göstermektedir:
>>> list(range(1, 10, 2))
[1, 3, 5, 7, 9]
Eğer adım sayısı negatif ise, başlangıç parametresi bitiş parametresinden büyük olmalıdır.
>>> list(range(20, 4, -5))
[20, 15, 10, 5]
yoksa sonuç boş bir liste olacaktır.
>>> list(range(10, 20, -5))
[]
9.8 Listeler değiştirilebilir
Karakter dizilerinin aksine listeler değiştirilebilir (mutable), yani öğelerini değiştirebildiğimiz yapılardır. Köşeli parantez işlecini sol tarafta kullanarak, listenin öğelerini güncelleyebiliriz:
>>> fruit = ["banana", "apple", "quince"]
>>> fruit[0] = "pear"
>>> fruit[-1] = "orange"
>>> print(fruit)
['pear', 'apple', 'orange']
Listeye uyguladığımız köşe parantezi işleci ifadenin herhangi bir yerinde yer alabilir. Atamanın sol tarafından yer aldığında, listenin bir öğesini değiştirir, yukarıdaki örnekte gördüğümüz üzere fruit listesinin ilk öğesi 'banana'‘dan 'pear'‘a, ve son öğesi 'quince'‘tan 'orange'‘a değiştirilmiştir. Bir listenin öğesine yapılan atamaya öğe ataması adı verilmektedir. Öğe atamaları karakter dizilerinde işe yaramamaktadır:
>>> my_string = 'TEST'
>>> my_string[2] = 'X'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
ancak listelerde işe yaramaktadır:
>>> my_list = ['T', 'E', 'S', 'T']
>>> my_list[2] = 'X'
>>> my_list
['T', 'E', 'X', 'T']
Dilim işleciyle listenin birden fazla öğesini tek seferde güncelleyebiliriz:
>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> a_list[1:3] = ['x', 'y']
>>> print(a_list)
['a', 'x', 'y', 'd', 'e', 'f']
Ayrıca ilgili öğelerin yerine boş liste atayarak öğeleri silebiliriz:
>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> a_list[1:3] = []
>>> print(a_list)
['a', 'd', 'e', 'f']
Ve boş bir dilimin arasına yeni öğeler sıkıştırarak listede istediğimiz konuma yeni öğeler ekleyebiliriz:
>>> a_list = ['a', 'd', 'f']
>>> a_list[1:1] = ['b', 'c']
>>> print(a_list)
['a', 'b', 'c', 'd', 'f']
>>> a_list[4:4] = ['e']
>>> print(a_list)
['a', 'b', 'c', 'd', 'e', 'f']
9.9 Liste silme
Dilimleri kullanarak liste öğelerini silmek uygunsuz ve hataya yatkın olacaktır. Python daha okunaklı bir alternatif yöntem sunmaktadır.
del listeden öğe silmekte kullanılır:
>>> a = ['one', 'two', 'three']
>>> del a[1]
>>> a
['one', 'three']
Tahmin edebileceğiniz gibi del negatif indisleri destekler ve varolmayan bir indis kullanıldığında çalışma zamanı hatası üretir.
Dilim işlemini del için bir indis olarak kullanabilirsiniz:
>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del a_list[1:5]
>>> print(a_list)
['a', 'f']
Her zamanki gibi, dilimler ikinci indise kadar tüm öğeleri seçer, ama ikinci indisteki öğeyi seçmez.
9.10 Nesneler ve değerler
Eğer aşağıdaki atama cümlelerini çalıştırırsak,
a = "banana"
b = "banana"
a ve b‘nin "banana" karakterlerini içeren karakter dizilerini gösterdiğini biliriz. Ancak aynı karakter dizisine gösterip göstermediklerini bilemeyiz.
İki olası durum vardır:

Bir durumda, a ve b farklı şeyleri gösterir ama değerleri aynıdır. İkinci durumda aynı şeyi gösterirler. Bu şeylerin bir ismi vardır — nesneler olarak adlandırılmaktadır. Ve nesne bir değişken tarafından gösterilebilen (referans edilen) bir şeydir.
Her nesne bir tekil tanımlayıcı (identifier)ya sahiptir, bu tanımlayıcıyı id fonksiyonuyla öğrenebiliriz. a ve b‘nin tanımlayıcılarını ekranda görüntüleyerek aynı nesneyi gösterip göstermektediklerini anlayabiliriz.
>>> id(a)
135044008
>>> id(b)
135044008
Gerçekte, aynı tanımlayıcıyı iki kere görüntülemiş olduk, bunun anlamı Python a ve b‘nin her ikisinin göstermesi için tek bir karakter dizisi yaramıştır. Sizin id değeriniz muhtemelen farklı olacaktır.
İlginç bir şekilde, listeler farklı şekilde davranmaktadır. İki liste yarattığımızda, iki nesne elde ederiz:
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> id(a)
135045528
>>> id(b)
135041704
Diyagram şu şekilde olacaktır:

a ve b aynı değere sahiptir, fakat aynı nesneyi göstermemektedir.
9.11 Takma isimler
Değişkenler nesneleri gösterdiğine göre, eğer bir değişkeni bir başkasına atarsak, her iki değişken de aynı nesneyi gösterecektir:
>>> a = [1, 2, 3]
>>> b = a
>>> id(a) == id(b)
True
Bu durumda, durum diyagramı şu şekilde olacaktır:

Aynı liste farklı isimlere sahip olduğu için, a ve b, takma isimlendirilmiş (aliased) olduğunu söyleriz. Bir takma isime yapılan değişiklikler diğerini de etkiler:
>>> b[0] = 5
>>> print(a)
[5, 2, 3]
Bu davranış yararlı olsa da, bazı durumlarda beklenmeyen ve istenmeyen bir davranıştır. Genel olarak, değiştirilebilir nesnelerle çalışırken takma isimlerden uzak durmak daha güvenli olacaktır. Elbette, değiştirilemeyen nesneler için, herhangi bir problem yoktur. Bu Python’un karakter dizilerini ekonomi için takma isimlerle (farklı değişkenler için aynı karakter dizilerini kullanmasının) isimlendirmesinin bir nedenidir.
9.12 Listeleri klonlama
Eğer bir listeyi değiştirmek ama asıl kopyayı da korumak istiyorsak, listenin sadece referansının değil kendisinin bir kopyasını oluşturabilmemiz gerekmektedir. Bu sürece bazen kopyalama ile oluşan karışıklığı önlemek için klonlama adı verilmektedir.
Bir listeyi klonlamanın en kolay yolu dilim işlecini kullanmaktır:
>>> a = [1, 2, 3]
>>> b = a[:]
>>> print(b)
[1, 2, 3]
a‘nın herhangi bir dilimini almak yeni bir liste yaratır. Yukarıdaki örnekteki durumda dilimde listenin hepsi yer almaktadır.
Şimdi a için endişelenmeden b‘ye istediğimiz değişiklikleri yapmakta özgürüz:
>>> b[0] = 5
>>> print(a)
[1, 2, 3]
9.13 Listeler ve for döngüleri
for döngüsü listeler için de çalışmaktadır. for döngüsünün genel söz dizimi şu şekildedir:
for DEĞİŞKEN in LİSTE:
GÖVDE
Bu cümle aşağıdakiyle aynı işlevi görür:
i = 0
while i < len(LİSTE):
DEĞİŞKEN = LİSTE[i]
GÖVDE
i += 1
for döngüsü daha sadedir çünkü döngü değişkeni, i‘den bizi kurtarmaktadır. Daha önceki döngünün for döngüsüyle yazılmış halini aşağıda inceleyebilirsiniz.
for horseman in horsemen:
print(horseman)
Neredeyse İngilizce dilindeki gibi okunacaktır: For (every) horseman in (the list of) horsemen, print(the name of the) horseman. (atlılar listesindeki her bir atlı için atlının adını yazdır )
for döngüsünde herhangi bir liste ifadesi kullanılabilir:
for number in range(20):
if number % 3 == 0:
print (number)
for fruit in ["banana", "apple", "quince"]:
print("I like to eat " + fruit + "s!")
İlk örnek 0 ile 19 arasındaki 3’ün katlarını yazdırır. İkinci örnek değişik meyveler için ilgiyi ekranda görüntüler.
Listeler değiştirilebilir olduğu için, bir listeyi dolaşarak her bir öğesini değiştirmek istenen bir özelliktir. Aşağıdaki örnek 1‘den 5‘e tüm sayıların karesini almaktadır:
numbers = [1, 2, 3, 4, 5]
for index in range(len(numbers)):
numbers[index] = numbers[index]**2
Bir süre range(len(numbers)) hakkında düşünüp nasıl çalıştığını anlamaya çabalayın. Burada listedeki hem değer hem de indise ihtiyaç duyuyoruz, bu yüzden kendisine yeni bir değer atayabiliriz.
Aşağıdaki kalıp bunu gerçekleştirmek için Python’un sağladığı ve sıklıkla kullanılan güzel bir yoldur:
numbers = [1, 2, 3, 4, 5]
for index, value in enumerate(numbers):
numbers[index] = value**2
enumerate listeyi dolaşırken hem indisi hem de onunla ilişkili değeri üretir. Aşağıdaki örneği çalıştırarak enumerate‘in nasıl çalıştığını daha açık bir şekilde anlamaya çalışın:
>>> for index, value in enumerate(['banana', 'apple', 'pear', 'quince']):
... print(index, value)
...
0 banana
1 apple
2 pear
3 quince
>>>
9.14 Liste parametreler
Bir listeyi argüman olarak geçirmek gerçekte listeye bir referans geçirir, listenin bir kopyasını değil. Listeler değiştirilebilir olduğu için parametreye yapılan bir değişiklik asıl listeyi, argümanı da değiştirecektir. Örneğin, aşağıdaki fonksiyon bir listeyi argüman olarak alır ve her öğesini 2 ile çarpar:
def double_stuff(a_list):
for index, value in enumerate(a_list):
a_list[index] = 2 * value
Eğer double_stuff fonksiyonunu ch09.py isminde bir dosyaya koyarsak, aşağıdaki şekilde çalışmasını sınayabiliriz:
>>> from ch09 import double_stuff
>>> things = [2, 5, 'Spam', 9.5]
>>> double_stuff(things)
>>> things
[4, 10, 'SpamSpam', 19.0]
>>>
a_list parametresi ve things değişkeni aynı nesnenin takma isimleridir. Durum diyagramı şu şekilde olacaktır:
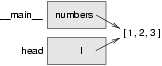
Liste nesnesi iki çerçeveyle paylaşıldığı için, aralarında çizdik.
Eğer bir fonksiyon liste parametreyi değiştirirse, çağıran kısım da değişikliği görür.
9.15 Saf (pure) fonksiyonlar ve değiştiriciler (modifiers)
Listeleri argüman olarak alıp çalışma esnasında onları değiştiren fonksiyonlara değiştiriciler adı verilir ve oluşan değişiklikler yan etkiler (side effects) olarak isimlendirilir.
Saf fonksiyon yan etkiler üretmez. Çağıran programla sadece parametrelerle haberleşir, parametreleri değiştirmez, bir dönüş değeri döndürür. Aşağıdaki double_stuff fonksiyonunun saf fonksiyon şeklinde yazılmış halini görebilirsiniz:
def double_stuff(a_list):
new_list = []
for value in a_list:
new_list += [2 * value]
return new_list
double_stuff fonksiyonunun bu sürümü argümanları değiştirmez:
>>> from ch09 import double_stuff
>>> things = [2, 5, 'Spam', 9.5]
>>> double_stuff(things)
[4, 10, 'SpamSpam', 19.0]
>>> things
[2, 5, 'Spam', 9.5]
>>>
things‘i değiştirmek için double_stuff saf fonksiyonunu kullanabilmek için, geri dönüş değerini tekrar things‘e atamanız gerekir:
>>> things = double_stuff(things)
>>> things
[4, 10, 'SpamSpam', 19.0]
>>>
9.16 Hangisi daha iyi?
Değiştiricilerle yapabildiğiniz herşeyi saf fonksiyonlarla da yapabilirsiniz. Gerçekte bazı programlama dilleri sadece saf fonksiyonlara izin vermektedir. Saf fonksiyonları kullanan programların değiştiricileri kullanan programlara göre daha hızlı geliştirildiği ve daha az hataya yatkın olduklarına dair bazı kanıtlar vardır. Yine de değiştiricilerin uygun olduğu bazı durumlar vardır, ve bazı durumlarda fonksiyonel programlar daha az verimlidir.
Genel olarak, mantıklı olduğu her durumda saf fonksiyonları kullanmanızı, çetin bir avantaj olduğunda değiştiricilere başvurmanızı öneriyoruz. Bu yaklaşım fonksiyonel programlama tarzı olarak adlandırılabilir.
9.17 İçiçe listeler
İç liste bir başka listenin öğesi olarak gözüken listedir. Aşağıdaki listede, 3 indisine sahip öğe bir iç listedir:
>>> nested = ["hello", 2.0, 5, [10, 20]]
Eğer nested[3] ifadesini ekrana yazdırırsak, [10, 20] sonucunu elde ederiz. İçteki listeden bir öğe elde etmek için iki adım izlememiz gerekir:
>>> elem = nested[3]
>>> elem[0]
10
Veya bu adımları birleştiririz:
>>> nested[3][1]
20
Köşeli parantez işleçleri soldan sağa doğru işlenir, bu ifade içteki nested listesinin üçüncü öğesinin ilk öğesini döndürür.
9.18 Matrisler
İçiçe listeler genellikle matrisleri temsil etmek için kullanılır. Örneğin, şu matris:

şu şekilde temsil edilebilir:
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
matrix üç öğesi olan, ve her bir öğesi matrisin bir satırı olan bir listedir. Köşeli parantez işleciyle matrisin bir satırını seçebiliriz:
>>> matrix[1]
[4, 5, 6]
Veya matrisin tek bir öğesini çift indis biçimini kullanarak seçebiliriz:
>>> matrix[1][1]
5
İlk indis satırı seçer, ikinci indis sütunu seçer. Bu şekilde matris temsili sık kullanılan bir yöntem olsa da, tek yöntem değildir. Basit bir değişiklik satır listesi yerine sütun listesi kullanımıdır. Daha sonra sözlük aracılığıyla daha radikal bir yöntemi göreceğiz.
9.19 Test güdümlü geliştirme (TDD)
Test güdümlü geliştirme (TDD) bir yazılım geliştirme pratiğidir. Bu pratikte küçük peşpeşe adımlar kullanılır. Bu adımlar otomatikleştirilmiş testlerle güdülenmiştir. İstenen özelliği veya ilerlemeyi sınayan testler önce yazılır.
Doctest TDD kullanımını göstermemizi oldukça kolaylaştırmaktadır. Verilen rows ve columns argümanlarından yararlanarak satır ve sütun matrisi yaratan bir fonksiyona ihtiyaç duyduğumuzu varsayalım.
İlk önce ismi matrices.py olan bir dosyada bu fonksiyon için bir test hazırlıyoruz:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
"""
if __name__ == '__main__':
import doctest
doctest.testmod()
Bu programı çalıştırdığımız çöken bir testle karşılaşırız:
**********************************************************************
File "matrices.py", line 3, in __main__.make_matrix
Failed example:
make_matrix(3, 5)
Expected:
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
Got nothing
**********************************************************************
1 items had failures:
1 of 1 in __main__.make_matrix
***Test Failed*** 1 failures.
Test çöker çünkü henüz fonksiyonun gövdesi sadece üç tırnakla sınırlanmış bir karakter dizisi içerir, bir geri dönüş cümlesi yoktur. Bu yüzden None döndürür. Testimizde sıfırlardan oluşan 3 satır ve 5 sütun içeren bir matris döndürmesini bekliyoruz.
TDD’de testi geçecek çözümü yazarken kural çalışan en basit şeyi kullanmaktır, bu durumda beklenen sonucu döndüren bir şey yazabiliriz:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
"""
return [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
Programı çalıştırdığımızda testleri geçer, ama bu gerçekleştirimimiz make_matrix fonksiyonunun hep aynı değeri döndürmesini, yani istediğimiz şeyi yapmamasını sağlamaktadır. Bunu düzeltmek için, önce iyileştirmemizi bir test ekleyerek güdülüyoruz:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
>>> make_matrix(4, 2)
[[0, 0], [0, 0], [0, 0], [0, 0]]
"""
return [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
beklediğimiz gibi test çöker:
**********************************************************************
File "matrices.py", line 5, in __main__.make_matrix
Failed example:
make_matrix(4, 2)
Expected:
[[0, 0], [0, 0], [0, 0], [0, 0]]
Got:
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
**********************************************************************
1 items had failures:
1 of 2 in __main__.make_matrix
***Test Failed*** 1 failures.
Bu tekniğe test güdümlü adı verilmektedir çünkü sadece çöken test varken, bu testlerin başarılı olması için kod yazılması gerektiğini söyler. Çöken testle güdülenmiş bir şekilde, daha genel bir çözüm üretebiliriz:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
>>> make_matrix(4, 2)
[[0, 0], [0, 0], [0, 0], [0, 0]]
"""
return [[0] * columns] * rows
Bu çözüm çalışıyor gibi gözüküyor, işimizin bittiğini düşünebiliriz, ancak yeni fonksiyonu daha sonra denediğimizde bir hata keşfederiz:
>>> from matrices import *
>>> m = make_matrix(4, 3)
>>> m
[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> m[1][2] = 7
>>> m
[[0, 0, 7], [0, 0, 7], [0, 0, 7], [0, 0, 7]]
>>>
İkinci satır ve üçüncü sütundaki öğeye 7 değerini atamak istedik, ama tüm üçüncü sütundaki öğelerin 7 olduğunu görüyoruz!
İncelediğimizde, çözümümüzün her bir satırın diğer satırların bir takma ismi olduğunu farkederiz. Bu gerçekte yapmak istediğimiz bir şey değil, bu yüzden problemi çözmek için çökecek olan testi yazarız:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
>>> make_matrix(4, 2)
[[0, 0], [0, 0], [0, 0], [0, 0]]
>>> m = make_matrix(4, 2)
>>> m[1][1] = 7
>>> m
[[0, 0], [0, 7], [0, 0], [0, 0]]
"""
return [[0] * columns] * rows
Çözülecek çöken testle birlikte, daha iyi bir çözüm için güdülenmiş oluruz:
def make_matrix(rows, columns):
"""
>>> make_matrix(3, 5)
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
>>> make_matrix(4, 2)
[[0, 0], [0, 0], [0, 0], [0, 0]]
>>> m = make_matrix(4, 2)
>>> m[1][1] = 7
>>> m
[[0, 0], [0, 7], [0, 0], [0, 0]]
"""
matrix = []
for row in range(rows):
matrix += [[0] * columns]
return matrix
TDD kullanımının bizim yazılım geliştirme sürecine bir çok yararı vardır. TDD:
- çözmeye çalıştığımız problemi çözmeden önce problem hakkında somut bir şekilde düşünmemize yardımcı olur.
- karmaşık problemleri daha küçük, basit problemlere parçalamamız ve büyük problemi çözmeyi adım adım gerçekleştirmemiz için bizi cesaretlendirir
- yazılımımızın iyi geliştirilmiş bir otomatik test kümesine sahip olmasını sağlar, böylece daha sonraki eklemeler ve geliştirmeler daha güvenli bir şekilde yapılır.
9.20 Karakter dizileri ve listeler
Python list adı verilen bir komuta sahiptir, bu komut bir dizi tipini alıp onun öğelerinden liste oluşturur:
>>> list("Crunchy Frog")
['C', 'r', 'u', 'n', 'c', 'h', 'y', ' ', 'F', 'r', 'o', 'g']
Ayrıca bir str komutu vardır, herhangi bir Python değerini argüman olarak alıp o değerin karakter dizisi temsilini döndürür.
>>> str(5)
'5'
>>> str(None)
'None'
>>> str(list("nope"))
"['n', 'o', 'p', 'e']"
Son örnekten gördüğümüz üzere, str karakterlerden oluşan bir listeyi birleştirmek için kullanılamamaktadır. Bunu yapabilmek için join fonksiyonunu kullanmamız gerekir:
>>> char_list = list("Frog")
>>> char_list
['F', 'r', 'o', 'g']
>>> ''.join(char_list)
'Frog'
split fonksiyonu bir karakter dizisini kelimelerden oluşan bir listeye ayrıştırır. Varsayılan olarak beyaz boşluk karakterleri kelime sınırları olarak kabul edilir:
>>> song = "The rain in Spain..."
>>> song.split()
['The', 'rain', 'in', 'Spain...']
İsteğe bağlı bir argüman olan ayırıcı (delimeter) kelime sınırlarını belirleyecek karakterleri ifade etmek için kullanılabilir. Aşağıdaki örnekler ai karakter dizisini ayırıcı olarak kullanmaktadır:
>>> song.split('ai')
['The r', 'n in Sp', 'n...']
Ayırıcının listede yer almadığına dikkat edin.
join fonksiyonu split‘in karşıtıdır. İki argüman alır: karakter dizisi listesi ve sonuç karakter dizisinde görünecek listedeki her bir öğe arasında koyulacak bir ayırıcı (separator).
>>> words = ['crunchy', 'raw', 'unboned', 'real', 'dead', 'frog']
>>> ' '.join(words)
'crunchy raw unboned real dead frog'
>>> '**'.join(words)
'crunchy**raw**unboned**real**dead**frog'
9.21 Sözlük
- liste
- Nesnelerin isimlendirilmiş bir kolleksiyonu, her bir öğe bir indis ile tanımlanır.
- indis
- Bir listenin öğesini gösteren, temsil eden tamsayı değişken veya değer
- öğe
- Listedeki (veya diğer dizilerdeki) değerlerden biri. Köşeli parantez işleci lsitedeği öğeleri seçer.
- dizi
- Sıralı öğe kümesinden oluşan herhangi bir veri tipi, her bir öğe bir indis ile tanımlanır.
- iç liste
- Bir başka listenin öğesi olan liste
- adım sayısı
- Lineer bir dizideki peşpeşe öğeler arasındaki aralık miktarıdır.
rangefonksiyonunun üçüncü (veya isteğe bağlı) argümanına adım sayısı adı verilir. Eğer belirtilmezse varsayılan değeri 1’dir. - liste dolaşma
- Listedeki her bir öğeye sıralı bir şekilde erişmedir.
- değiştirilebilir (mutable) tip
- Öğeleri değiştirilebilen veri tipidir. Tüm değiştirilebilir tipler bileşik tiplerdir. Listeler değiştirilebilir veri tipidir; karakter dizileri değildir.
- nesne
- Değişkenlerin gösterdiği şey
- takma isimler
- Aynı nesneyi gösteren farklı değişkenlerdir.
- klonlama
- Var olan nesneyle aynı değere farklı yeni bir nesne yaratma. Nesneye olan referansı kopyalama işlemi takma isim oluştururken nesneyi klonlamaz.
- değiştirici
- Fonksiyon gövdesi için argümanları değiştiren fonksiyonlardır. Sadece değiştirilebilir tipler değiştiricilerle değiştirilebilir.
- yan etki
- Programın durumunda bir fonksiyonu çağırarak yapılan ancak fonksiyonun geri dönüş değerini okuyarak gerçekleşmeyen değişikliktir. Yan etkiler sadece değiştiricilerle üretilebilir.
- saf fonksiyon
- Yan etkisi olmayan fonksiyondur. Saf fonksiyonlar sadece geri dönüş değerlerini döndürerek çağıran programa değişiklik yaparlar.
- test güdümlü geliştirme (TDD)
- Küçük, arttırımlı adımlar şeklinde istenen özelliğin geliştirildiği, her bir adımın önce yazılan otomatik testlerle güdülendiği yazılım geliştirme pratiğidir. Önce testler yazılarak istenen özellik ve geliştirmeler için güdü sağlanır.(daha ayrıntılı bilgi için Test-driven development wikipedia yazısını inceleyebilirsiniz.)
- ayırıcı
- Karakter dizisinin nereden ayrılacağını belirten bir karakter veya karakter dizisi.
9.22 Alıştırmalar
- Aşağıdaki listeyi dolaşan ve her öğenin boyutunu yazan bir döngü yazın:
['spam!', 1, ['Brie', 'Roquefort', 'Pol le Veq'], [1, 2, 3]]
len‘e tamsayı gönderince ne oluyor? 1‘i 'one'‘a çevirerek çözümünüzü tekrar çalıştırın.
ch09e02.pyismindeki bir dosyaya aşağıdaki içeriği yazın:
# doctestleri buraya ekleyin:
"""
"""
# Python kodunuzu buraya ekleyin:
if __name__ == '__main__':
import doctest
doctest.testmod()
Aşağıdaki her bir dostest kümesini dosyanın üstündeki docstringe koyup ve bu testlerin geçmesi için gereken Python kodlarını yazın.
-
""" >>> a_list[3] 42 >>> a_list[6] 'Ni!' >>> len(a_list) 8 """ -
""" >>> b_list[1:] ['Stills', 'Nash'] >>> group = b_list + c_list >>> group[-1] 'Young' """ -
""" >>> 'war' in mystery_list False >>> 'peace' in mystery_list True >>> 'justice' in mystery_list True >>> 'oppression' in mystery_list False >>> 'equality' in mystery_list True """ -
""" >>> range(a, b, c) [5, 9, 13, 17] """
Her adımda bir doctest kümesini ekleyin. Önceki eklenen test başarılı olmadan, yeni doctestler eklenmemelidir.
- Python yorumlayıcısının aşağıdakilere tepkisi nedir?
>>> range(10, 0, -2)
range fonksiyonunun üç argümanı sırasıyla başlangıç, bitiş ve adımdır. Bu örnekte başlangıç, bitiş‘ten daha büyüktür. başlangıç < bitiş ve adım < 0 durumunda ne olur? başlangıç, bitiş ve adım arasındaki ilişki hakkında bir kural yazınız.
- durum diyagramı sorusu
a = [1, 2, 3]
b = a[:]
b[0] = 5
a ve b için üçüncü satır işlenmeden ve işlendikten sonra durum diyagramı çiziniz.
- Aşağıdaki programın çıktısı ne olur?
this = ['I', 'am', 'not', 'a', 'crook']
that = ['I', 'am', 'not', 'a', 'crook']
print("Test 1: %s" % (id(this) == id(that)))
that = this
print("Test 2: %s" % (id(this) == id(that)))
Sonucun ayrıntılı bir açıklamasını yapınız.
ch09e06.pyisminde bir dosya açıp, 2. alıştırmadaki aynı prosedürü aşağıdaki doctestler başarılı olacak şekilde tekrarlayın:
-
""" >>> 13 in junk True >>> del junk[4] >>> junk [3, 7, 9, 10, 17, 21, 24, 27] >>> del junk[a:b] >>> junk [3, 7, 27] """ -
""" >>> nlist[2][1] 0 >>> nlist[0][2] 17 >>> nlist[1][1] 5 """ -
""" >>> import string >>> string.split(message, '??') ['this', 'and', 'that'] """
- Aynı uzunlukta olan ve sayılardan oluşan iki liste argümanı alan ve her bir listede birbirine karşılık gelen sayıların toplamını yeni bir liste olarak döndüren
add_lists(a, b)fonksiyonunu yazınız.
def add_lists(a, b):
"""
>>> add_lists([1, 1], [1, 1])
[2, 2]
>>> add_lists([1, 2], [1, 4])
[2, 6]
>>> add_lists([1, 2, 1], [1, 4, 3])
[2, 6, 4]
"""
add_lists yukarıdaki doctestleri geçmelidir.
- Aynı uzunlukta olan ve sayılardan oluşan iki liste argümanı alan ve her listede birbirine karşılık gelen sayılarının çarpımlarını yeni bir liste olarak döndüren
mult_lists(a, b)fonksiyonunu yazınız.
def mult_lists(a, b):
"""
>>> mult_lists([1, 1], [1, 1])
2
>>> mult_lists([1, 2], [1, 4])
9
>>> mult_lists([1, 2, 1], [1, 4, 3])
12
"""
mult_lists yukarıdaki doctestleri geçmelidir.
- Test güdümlü geliştirme bölümünde anlatılan
matrices.pyprogramına aşağıdaki iki fonksiyonu ekleyin:
def add_row(matrix):
"""
>>> m = [[0, 0], [0, 0]]
>>> add_row(m)
[[0, 0], [0, 0], [0, 0]]
>>> n = [[3, 2, 5], [1, 4, 7]]
>>> add_row(n)
[[3, 2, 5], [1, 4, 7], [0, 0, 0]]
>>> n
[[3, 2, 5], [1, 4, 7]]
"""
def add_column(matrix):
"""
>>> m = [[0, 0], [0, 0]]
>>> add_column(m)
[[0, 0, 0], [0, 0, 0]]
>>> n = [[3, 2], [5, 1], [4, 7]]
>>> add_column(n)
[[3, 2, 0], [5, 1, 0], [4, 7, 0]]
>>> n
[[3, 2], [5, 1], [4, 7]]
"""
Yeni fonksiyonlarınız doctestleri geçmelidir. Her fonksiyondaki son doctest add_row ve add_column fonksiyonlarının saf fonksiyon olduğunu garantilemek için yazılmıştır.
m1vem2‘yi toplayan ve toplamlarını yeni bir matris olarak döndürenadd_matrices(m1, m2)fonksiyonunu yazınız.m1vem2aynı büyüklükte olduğunu kabul edebilirsiniz. Matrislerini birbirine karşılık gelen değerlerini toplayarak toplarsınız.
def add_matrices(m1, m2):
"""
>>> a = [[1, 2], [3, 4]]
>>> b = [[2, 2], [2, 2]]
>>> add_matrices(a, b)
[[3, 4], [5, 6]]
>>> c = [[8, 2], [3, 4], [5, 7]]
>>> d = [[3, 2], [9, 2], [10, 12]]
>>> add_matrices(c, d)
[[11, 4], [12, 6], [15, 19]]
>>> c
[[8, 2], [3, 4], [5, 7]]
>>> d
[[3, 2], [9, 2], [10, 12]]
"""
Yeni fonksiyonunuzu matrices.py programına ekleyin, ve yukarıdaki doctestleri geçmesini sağlayın. Son iki doctest add_matrices fonksiyonunun saf fonksiyon olmasını sağlamak içindir.
- Bir matrisi,
m, bir büyüklük,nile çarpanscalar_mult(n, m)fonksiyonunu yazın.
def scalar_mult(n, m):
"""
>>> a = [[1, 2], [3, 4]]
>>> scalar_mult(3, a)
[[3, 6], [9, 12]]
>>> b = [[3, 5, 7], [1, 1, 1], [0, 2, 0], [2, 2, 3]]
>>> scalar_mult(10, b)
[[30, 50, 70], [10, 10, 10], [0, 20, 0], [20, 20, 30]]
>>> b
[[3, 5, 7], [1, 1, 1], [0, 2, 0], [2, 2, 3]]
"""
Fonksiyonunuzu matrices.py programına ekleyin ve yukarıdaki doctestleri geçmesini sağlayın.
- matris soruları
def row_times_column(m1, row, m2, column):
"""
>>> row_times_column([[1, 2], [3, 4]], 0, [[5, 6], [7, 8]], 0)
19
>>> row_times_column([[1, 2], [3, 4]], 0, [[5, 6], [7, 8]], 1)
22
>>> row_times_column([[1, 2], [3, 4]], 1, [[5, 6], [7, 8]], 0)
43
>>> row_times_column([[1, 2], [3, 4]], 1, [[5, 6], [7, 8]], 1)
50
"""
def matrix_mult(m1, m2):
"""
>>> matrix_mult([[1, 2], [3, 4]], [[5, 6], [7, 8]])
[[19, 22], [43, 50]]
>>> matrix_mult([[1, 2, 3], [4, 5, 6]], [[7, 8], [9, 1], [2, 3]])
[[31, 19], [85, 55]]
>>> matrix_mult([[7, 8], [9, 1], [2, 3]], [[1, 2, 3], [4, 5, 6]])
[[39, 54, 69], [13, 23, 33], [14, 19, 24]]
"""
Yeni fonksiyonlarını matrices.py programına ekleyin ve yukarıdaki doctestleri geçmesini sağlayın.
skarakter dizisindeki tümoldolan yerlerinewile değiştirenreplace(s, old, new)fonksiyonunu yazınız.
def replace(s, old, new):
"""
>>> replace('Mississippi', 'i', 'I')
'MIssIssIppI'
>>> s = 'I love spom! Spom is my favorite food. Spom, spom, spom, yum!'
>>> replace(s, 'om', 'am')
'I love spam! Spam is my favorite food. Spam, spam, spam, yum!'
>>> replace(s, 'o', 'a')
'I lave spam! Spam is my favarite faad. Spam, spam, spam, yum!'
"""
Çözümünüz yukarıdaki doctestleri sağlamalıdır.İpucu:split ve join kullanın.
Yorumlar